捷速OCR文字识别软件是一款非常实用的文字识别应用软件,该应用的功能十分的强大,相信平时经常需要内容转换的用户一定在熟悉不过了,它的操作非常的简单易上手,在主界面内排版了多项实用的功能,非常的简约直观,软件内置极其高科技智能的识别系统内核,具备了极其精准的文字识别纠正错误和图像的处理功能,可以轻松的帮助用户将图片内容的数据转换成word、文字、等等多种其他的类型,像我们平时常用的BMP、JPG、GIF、PDF等等多种数据格式都能完美支持,可以大大的节省我们在办公时期内大量复杂的工作流程,使得工作效益更加的高效,是一款不可多得的实用工具,只是稍有每种不足的是需要收费才能使用,并且价格也不是特别的美丽,如果是经常需要使用的话可能会产生大量的费用,非常的不划算,但是好在小编带来了本款
捷速OCR文字识别软件免费破解版,在本版本中破解了它的收费特项,可以不花一分钱免费使用,免去一些不必要的费用,有兴趣的不妨快来试一试吧~
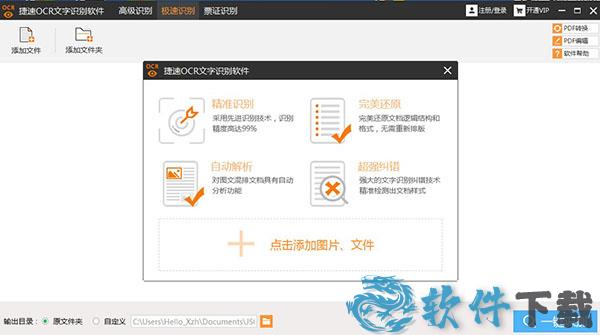
安装教程
1、在17软件下载站中下载到捷速ocr文字识别软件破解版资源压缩包并进行解压。
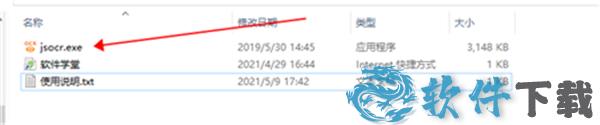
2、在解压后的文件内找到并双击“jsocr.exe”,进入安装界面。

3、仔细浏览且勾选同意用户许可协议。

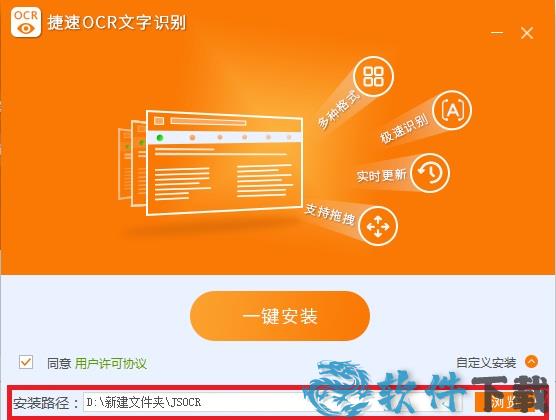
4、可以根据自己电脑的空间环境需求选择安装位置,软件默认安装在C:\Program Files (x86)\JSOCR。
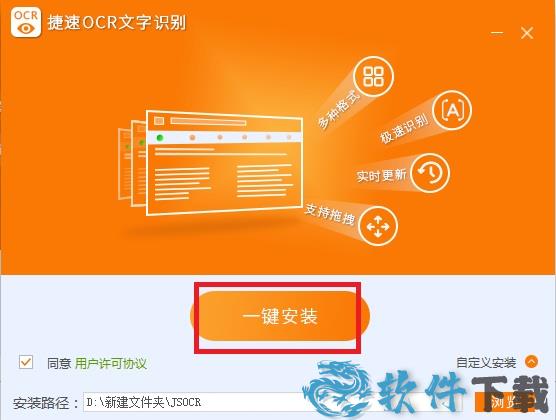
5.点击一键安装
6、稍微的等待一段时间,界面显示安装等待中。
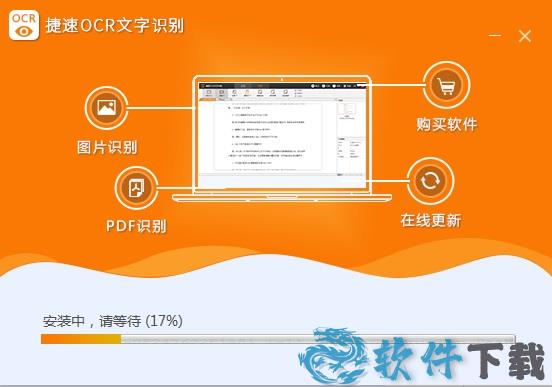
7、如下图,软件就算安装完成啦。
破解激活教程
1、在本站下载解压好软件破解版软件包后,双击运行一下“.exe”主程序,它会自动在桌面上创建快捷方式并且打开软件。注意此时的软件界面是有注册界面的,然后将软件关闭。
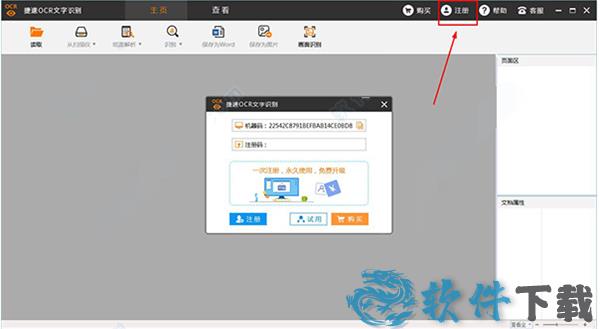
2、我们现在下载“捷速OCR文字识别 v3.0 破解补丁.exe”补丁,打开破解补丁后,点击“执行补丁”。

3、然后它会有一个打开弹出框,我们来到“C:Program Files (x86)JSOCR”目录下,选择“JSOCR.exe”,然后点击“打开”。
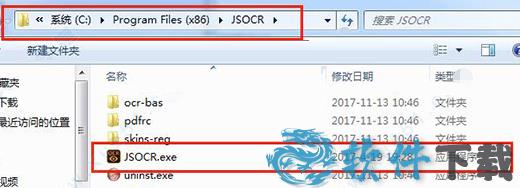
4、然后你就可以看到补丁成功的提示。
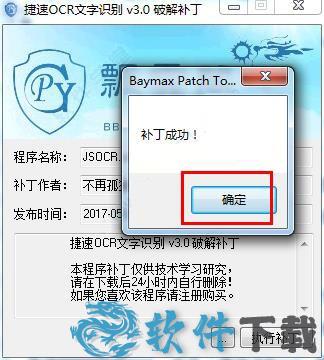
5、然后双击桌面上的快捷方式,你会发现软件界面不会再有注册界面了,说明软件破解成功,以后就可以免费使用捷速ocr文字识别软件破解版了。
注意:
若你在破解补丁时出现下面这样的弹出框,请点击“是”,然后再次执行补丁,来到“C:Program Files (x86)JSOCR”目录下,选择“JSOCR.exe”,打开,即可完成破解。
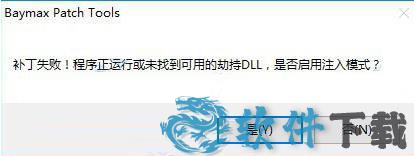
捷速ocr文字识别软件使用方法
第一步,首先我们需要将软件下载下来,然后安装到电脑里。
第二步,运行软件,软件默认是极速识别模式,可以自己换识别模式,然后把要识别的图片文件添加进来。
第三步,文件打开之后单击一件识别按钮,软件就会对文件进行识别处理了。
第四步,识别完成之后打开文件就可以看到识别效果了,是不是很不错啊。
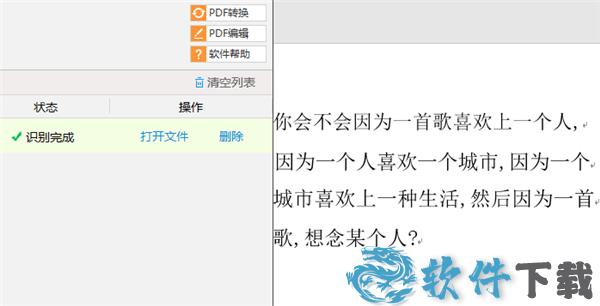
软件特点
1、捷速ocr文字识别软件破解版支持多种格式
图片转换立等可取:支持JPG、GIF、PNG、BMP、TIF图片文件格式拖曳上传可以在任意位置,将图片进行拖曳方式进行识别,也可以直接点击进行添加. 识别过程中会有数秒的等待时间,等识别完成系统会自动在桌面生成一个txt文件,可以通过系统直接打开,也可以打开文件所在目录。
2、支持拖拽
直接拖曳图片到软件,更方便,更快捷:支持拖曳上传可以在任意位置,将图片进行拖曳方式进行识别,也可以直接点击进行添加. 识别过程中会有数秒的等待时间,等识别完成系统会自动在桌面生成一个txt文件,可以通过系统直接打开,也可以打开文件所在目录。
3、识别速度快
无需进行繁琐操作步骤 实现一键式识别:软件的智能化程度非常高,所以简化了使用的操作步骤,实现一键式识别。如果使用过其它文字识别软件,一定知道软件的操作非常的繁琐,首先文件要进行预处理,文件添加后还要在软件中进行各种调整达到软件的识别要求才能进行识别,这些对于新手来说是难以接受的。软件自身拥有对文件进行处理的智能技术,文件添加完成只需要点击“开始转换”就能自动完成识别工作。
4、更新速度快
最新功能,实时更新,让您第一时间使用:系统每次发布更新都会提示是否选择更新? 更新时请误关闭系统或进行其他操作,以免操作数据丢失。
功能特点
1、精准识别文字信息:软件采用先进的OCR识别技术,高达99%的识别精度,轻松实现文档数字化。
2、完美还原文档格式:软件可一键读取文档,完美还原文档的逻辑结构和格式,无需重新录入和排版。
3、自动解析图文版面:软件对图文混排的文档具有自动分析功能,将文字区域划分出来后自动进行识别。
4、极速识别文本内容:软件具备高智能化识别内核,通过智能简化软件使用的操作步骤,实现极速识别。
5、强大识别纠错技术:软件提供更强大的文字识别纠错技术,精准地检测出文档样式、标题等内容。
6、改进图片处理算法:软件进一步改进图像处理算法,提高扫描文档显示质量,更好地识别拍摄文本。
常见问题解答
1、扫描仪功能无法使用?
答:请确认扫描仪的电源线、数据线都已经成功连接,以及电源指示灯是否显示正常。若是检查无误,可尝试重启电脑,再使用扫描仪功能。
2、识别后,保存为Word有文本框不易修改如何解决?
答:软件是根据用户提供的原件进行识别的,请确认下原件内容上是否具有文本框。
3、图片上的文字能够100%还原吗?
答:只要图片上的文字清晰,易于识别,大部分都是可以还原的。但若是文件上掺杂较多的表格、图标图片或是大量的公式,这样的文件识别效果会较差。
4、手机或相机拍摄的图片可以识别吗?
答:可以的。不过拍摄的图片需要尽可能的放正,不要有太多明显的扭曲。若是拍摄书籍的话,尽量让书页摊开保持平整。另,手机或相机存储的图片,尽量使用较高的分辨率。
5、所有的图片都可以转换吗?
答:捷速OCR文字识别软件支持PDF文件、扫描件、PNG图片、JPG图片、BMP图片、TIF等,支持大多数图片格式转换。
6、可以一次性识别多个文件吗?
答:可以的。用户可以直接选中多个文件进行识别,也可以直接在软件上添加文件夹进行文件识别。
7、识别后的文档只有一部分?
答:在选择识别功能时,没有选择“全部页面”,或是在解析内容时,并未选择解析“全部页面”,都有可能出现只识别当前页面的情况。
8、如何查看会员到期时间?
答:用户登录会员账号后,将鼠标移动到账号名下,即可查看到相关会员信息。
关于OCR光学字符识别
OCR (Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程;即,针对印刷体字符,
发展简史1.OCR的概念是在1929年由德国科学家Tausheck最先提出来的,后来美国科学家Handel也提出了利用技术对文字进行识别的想法。而最早对印刷体汉字识别进行研究的是IBM公司的Casey和Nagy,1966年他们发表了第一篇关于汉字识别的文章,采用了模板匹配法识别了1000个印刷体汉字。
2.早在60、70年代,世界各国就开始有OCR的研究,而研究的初期,多以文字的识别方法研究为主,且识别的文字仅为0至9的数字。以同样拥有方块文字的日本为例,1960年左右开始研究OCR的基本识别理论,初期以数字为对象,直至1965至1970年之间开始有一些简单的产品,如印刷文字的邮政编码识别系统,识别邮件上的邮政编码,帮助邮局作区域分信的作业;也因此至今邮政编码一直是各国所倡导的地址书写方式。
3.20世纪70年代初,日本的学者开始研究汉字识别,并做了大量的工作。中国在OCR技术方面的研究工作起步较晚,在70年代才开始对数字、英文字母及符号的识别进行研究,70年代末开始进行汉字识别的研究,到1986年,我国提出“863”高新科技研究计划,汉字识别的研究进入一个实质性的阶段,清华大学的丁晓青教授和中科院分别开发研究,相继推出了中文OCR产品,现为中国最领先汉字OCR技术。早期的OCR软件,由于识别率及产品化等多方面的因素,未能达到实际要求。同时,由于硬件设备成本高,运行速度慢,也没有达到实用的程度。只有个别部门,如信息部门、新闻出版单位等使用OCR软件。进入20世纪90年代以后,随着平台式扫描仪的广泛应用,以及我国信息自动化和办公自动化的普及,大大推动了OCR技术的进一步发展,使OCR的识别正确率、识别速度满足了广大用户的要求。
工作流程1.一个OCR识别系统,其目的很简单,只是要把影像作一个转换,使影像内的图形继续保存、有表格则表格内资料及影像内的文字,一律变成计算机文字,使能达到影像资料的储存量减少、识别出的文字可再使用及分析,当然也可节省因键盘输入的人力与时间。
从影像到结果输出,须经过影像输入、影像前处理、文字特征抽取、比对识别、最后经人工校正将认错的文字更正,将结果输出。
2.影像输入
欲经过OCR处理的标的物须透过光学仪器,如影像扫描仪、传真机或任何摄影器材,将影像转入计算机。科技的进步,扫描仪等的输入装置已制作的愈来愈精致,轻薄短小、品质也高,对OCR有相当大的帮助,扫描仪的分辨率使影像更清晰、扫除速度更增进OCR处理的效率。
3.影像预处理:影像预处理是OCR系统中,须解决问题最多的一个模块。影像须先将图片、表格及文字区域分离出来,甚至可将文章的编排方向、文章的提纲及内容主体区分开,而文字的大小及文字的字体亦可如原始文件一样的判断出来。
对待识别图像进行如下预处理,可以降低特征提取算法的难度,并能提高识别的精度。
4.二值化:由于彩色图像所含信息量过于巨大,在对图像中印刷体字符进行识别处理前,需要对图像进行二值化处理,使图像只包含黑色的前景信息和白色的背景信息,提升识别处理的效率和精确度。
5.图像降噪:由于待识别图像的品质受限于输入设备、环境、以及文档的印刷质量,在对图像中印刷体字符进行识别处理前,需要根据噪声的特征对待识别图像进行去噪处理,提升识别处理的精确度。
6.倾斜校正:由于扫描和拍摄过程涉及人工操作,输入计算机的待识别图像或多或少都会存在一些倾斜,在对图像中印刷体字符进行7.识别处理前,就需要进行图像方向检测,并校正图像方向。
8.文字特征抽取:单以识别率而言,特征抽取可说是 OCR的核心,用什么特征、怎么抽取,直接影响识别的好坏,也所以在OCR研究初期,特征抽取的研究报告特别的多。而特征可说是识别的筹码,简易的区分可分为两类:一为统计的特征,如文字区域内的黑/白点数比,当文字区分成好几个区域时,这一个个区域黑/白点数比之联合,就成了空间的一个数值向量,在比对时,基本的数学理论就足以应付了。而另一类特征为结构的特征,如文字影像细线化后,取得字的笔划端点、交叉点之数量及位置,或以笔划段为特征,配合特殊的比对方法,进行比对,市面上的线上手写输入软件的识别方法多以此种结构的方法为主。
9.对比数据库:当输入文字算完特征后,不管是用统计或结构的特征,都须有一比对数据库或特征数据库来进行比对,数据库的内容应包含所有欲识别的字集文字,根据与输入文字一样的特征抽取方法所得的特征群组。
对比识别1.这是可充分发挥数学运算理论的一个模块,根据不同的特征特性,选用不同的数学距离函数,较有名的比对方法有,欧式空间的比对方法、松弛比对法(Relaxation)、动态程序比对法(Dynamic Programming,DP),以及类神经网络的数据库建立及比对、HMM(Hidden Markov Model)…等著名的方法,为了使识别的结果更稳定,也有所谓的专家系统(Experts System)被提出,利用各种特征比对方法的相异互补性,使识别出的结果,其信心度特别的高。
2.字词后处理:由于OCR的识别率并无法达到百分之百,或想加强比对的正确性及信心值,一些除错或甚至帮忙更正的功能,也成为OCR系统中必要的一个模块。字词后处理就是一例,利用比对后的识别文字与其可能的相似候选字群中,根据前后的识别文字找出最合乎逻辑的词,做更正的功能。
3.字词数据库:为字词后处理所建立的词库。
人工校正1.OCR最后的关卡,在此之前,使用者可能只是拿支鼠标,跟着软件设计的节奏操作或仅是观看,而在此有可能须特别花使用者的精神及时间,去更正甚至找寻可能是OCR出错的地方。一个好的OCR软件,除了有一个稳定的影像处理及识别核心,以降低错误率外,人工校正的操作流程及其功能,亦影响OCR的处理效率,因此,文字影像与识别文字的对照,及其屏幕信息摆放的位置、还有每一识别文字的候选字功能、拒认字的功能、及字词后处理后特意标示出可能有问题的字词,都是为使用者设计尽量少使用键盘的一种功能,当然,不是说系统没显示出的文字就一定正确,就像完全由键盘输入的工作人员也会有出错的时候,这时要重新校正一次或能允许些许的错,就完全看使用单位的需求了。
2.结果输出
有人只要文本文件作部份文字的再使用之用,所以只要一般的文字文件、有人要漂漂亮亮的和输入文件一模一样,所以有原文重现的功能、有人注重表格内的文字,所以要和Excel等软件结合。无论怎么变化,都只是输出档案格式的变化而已。如果需要还原成原文一样格式,则在识别后,需要人工排版,耗时耗力。
热门评论
用心阁:这个版本延续了前几代所有的优势和特点,并在此基础上大大扩展了相关的功能特性,对我来说简直是出类拔萃,真的很不错。

 Ghost安装器绿色版 V1.6.10.6
Ghost安装器绿色版 V1.6.10.6 3DMark 11多国语言安装版(显卡测试工具) V1.0.5
3DMark 11多国语言安装版(显卡测试工具) V1.0.5 Microsoft.NET Framework正式安装版 V4.6.1
Microsoft.NET Framework正式安装版 V4.6.1 AIDA64 extreme绿色中文版(硬件检测) V6.10.5200
AIDA64 extreme绿色中文版(硬件检测) V6.10.5200 DirectX修复工具官方标准版(DirectX Repair) V4.0
DirectX修复工具官方标准版(DirectX Repair) V4.0 CPU-Z 32位绿色中文版(CPU检测软件) V1.9.7.0
CPU-Z 32位绿色中文版(CPU检测软件) V1.9.7.0 UPUPOO中文安装版(桌面动态壁纸) V1.3.4
UPUPOO中文安装版(桌面动态壁纸) V1.3.4 VMware Workstation Pro中文完整安装版 V14.1.3
VMware Workstation Pro中文完整安装版 V14.1.3 微PE工具箱64位官方安装版 V2.2
微PE工具箱64位官方安装版 V2.2 微PE工具箱官方安装版 V2.2
微PE工具箱官方安装版 V2.2


 今日头条官方正版 V8.8.8V8.8.8 / 43.90 MB
今日头条官方正版 V8.8.8V8.8.8 / 43.90 MB 音乐雷达安卓版 V13.26.0-230414V13.26.0-230414 / 29.34MB
音乐雷达安卓版 V13.26.0-230414V13.26.0-230414 / 29.34MB 扫描全能王安卓版 V6.20.0v1.0 / 92.05 MB
扫描全能王安卓版 V6.20.0v1.0 / 92.05 MB 万能空调遥控器破解版 V1.4v1.4 / 45.52MB
万能空调遥控器破解版 V1.4v1.4 / 45.52MB 佛教音乐安卓版 V3.3.5V3.3.5 / 59.50MB
佛教音乐安卓版 V3.3.5V3.3.5 / 59.50MB 百度文库免费版 V8.0.53 8.0.53 / 21.75 MB
百度文库免费版 V8.0.53 8.0.53 / 21.75 MB 萌宝挖挖挖手游安卓版 V1.0益智游戏
萌宝挖挖挖手游安卓版 V1.0益智游戏 街头音乐学院破解版 V1.0益智游戏
街头音乐学院破解版 V1.0益智游戏 粉红钢琴大师游戏官方版 V1.1益智游戏
粉红钢琴大师游戏官方版 V1.1益智游戏 三国杀单机版 V4.0.0模拟经营
三国杀单机版 V4.0.0模拟经营 是魔女哦免费版 V0.0.20益智游戏
是魔女哦免费版 V0.0.20益智游戏 全民接快递百度版 V1.0模拟经营
全民接快递百度版 V1.0模拟经营